Status dieses Dokuments
Dieser Abschnitt beschreibt den Status dieses Dokuments zur Zeit
seiner Veröffentlichung. Andere Dokumente können dieses
Dokument ersetzen. Eine Liste der aktuellen W3C-Veröffentlichungen
und die aktuelle Version dieses Technischen Berichts kann im Index der Technischen Berichte des W3C
unter http://www.w3.org/TR/ gefunden werden.
Dieses Dokument ist eine Arbeitsgruppenanmerkung, die von
der W3C-Arbeitsgruppe Semantic Web
Deployment [SWD-WG] und der XHTML2-Arbeitsgruppe des W3C
[XHTML2-WG] zusammen erstellt wurde.
Diese Arbeit ist Teil beider, der W3C Semantic Web
Activity und der HTML
Activity. Der Übergang dieses Dokuments in den Status einer
Arbeitsgruppenanmerkung geschieht gleichzeitig mit dem Übergang
der RDFa Syntax-Spezifikation in eine W3C-Empfehlung.
Diese Vesion von RDFa Primer enthält geringfügige
redaktionelle Änderungen zur vorhergehenden Version wie auch einen
kurzen zusätzlichen Abschnitt (4.1), der
Hinweise für diejenigen enthält, die neue verwandte
Vokabulare erzeugen möchten. Die Veränderungen werden detailiert
im Dokument mit den Unterschieden beschrieben. Die
Arbeitsgruppen haben Vorschläge erhalten, dieses Dokument
zu erweitern und die Gruppen könnten in Zukunft Inhalte
hinzufügen, setzen sich aber nicht dafür ein, dies zu tun.
(Anmerkung des Übersetzers: Frei übersetzt, dieses Dokument ist "ziemlich
stabil".)
Kommentare zu dieser Arbeitsgruppenanmerkung sind willkommen und
können an public-rdf-in-xhtml-tf@w3.org geschickt werden (Anm. des
Übersetzers: in englischer Sprache); bitte verwenden Sie
den Begriff "comment" in der Betreffzeile. Alle Mitteilungen an
diese Adresse sind im
öffentlichen Archiv einzusehen.
Veröffentlichungen als Arbeitsgruppenanmerkung bedeuten nicht
zwangsläufig, dass die W3C-Mitgliedschaft dieses Dokument billigt.
Dies ist ein Entwurf und er kann zu jeder Zeit von anderen Dokumenten
aktualisiert, ersetzt oder für veraltet erklärt werden. Es
ist nicht angemessen, dieses Dokument anders zu zitieren als unter
Bearbeitung.
Dieses Dokument wurde von Gruppen erstellt, die unter der
W3C Patent
Policy vom 5. Februar 2004 arbeiten. W3C unterhält eine öffentliche Liste
mit jeglichen Patentveröffentlichungen, die in Verbindung mit den
Ergebnissen der XHTML 2-Gruppe gemacht wurden und eine andere
öffentliche
Liste mit jeglichen Patentveröffentlichungen, die in Verbingung mit
den Ergebnissen der Arbeitsgruppe Semantic Web Deployment gemacht
wurden; diese Seiten enthalten ebenso Anweisungen zur Veröffentlichung
eines Patents. Ein Individuum, das tatsächliches Wissen über
ein Patent hat, das nach Glauben des Individuums
Essentielle
Ansprüche enthält, muss diese Informationen in
Übereinstimmung mit
Abschnitt
6 der W3C Patent Policy veröffentlichen.
1 Einleitung
Das Internet ist eine reiche, verteilte Quelle verbundener
Informationen, es ist hauptsächlich auf den menschlichen Gebrauch
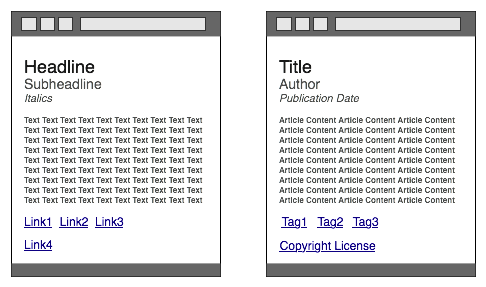
ausgerichtet. Auf einer üblichen Internetseite kann ein XHTML-Autor
eine Überschrift, dann eine Unterüberschrift, einen Bereich
mit kursivem Text, einige Absätze mit normaler Schriftgröße
und zuletzt ein paar Einzelwort-Verweise angeben. Internet-Browser werden
diesen Darstellungsanweisungen treu folgen. Jedoch versteht nur der menschliche
Verstand, dass die Überschrift in der Tat der Titel des Blogeintrags ist, die
Unterüberschrift den Autor angibt, der kursive Text das Datum der
Veröffentlichung des Artikels ist und die Einzelwort-Verweise Beschriftungen
für Kategorien sind. Die Lücke zwischen dem, was Programme verstehen
und dem, was Menschen verstehen, ist immens.
Links, was Browser sehen. Rechts, was Menschen
sehen. Können wir eine Brücke über diese Kluft bauen,
so dass Browser mehr von dem sehen, was wir sehen?
 |
Was wäre, wenn der Browser Informationen über die
Bedeutung der sichtbaren Elemente einer Internetseite empfängt?
Eine Abendgesellschaft, die in einem Blog bekanntgegeben wird, könnte
einfach in den Kalender eines Benutzers kopiert werden, die gesammten
Kontaktinformationen eines Autors in das Adressbuch des Benutzers. Benutzer
könnten früher angesehene Artikel über
Kategoriebeschriftungen (oft als Tags bezeichnet) automatisch wieder aufrufen.
Ein Foto, kopiert und eingefügt von einer Internetseite in einen
Schulbericht, würde einen Verweis zurück zur Fotografin mitbringen,
und ihr damit die angemessene Ehre erweisen. Werden Internetdaten, die
für Menschen gedacht sind, mit Hinweisen für Computerprogramme
erweitert, werden diese Programme bedeutend hilfreicher, denn sie
beginnen, die Datenstruktur zu verstehen.
RDFa gestattet XHTML-Autoren genau das. Mit ein paar einfachen
XHTML-Attributen können Autoren menschenlesbare Daten mit
maschinenlesbaren Indikatoren versehen, die Browser und andere Programme
interpretieren können. Eine Internetseite kann Bezeichner für so
einfache Dinge wie den Titel eines Artikels beinhalten oder so komplexe
wie das gesamte soziale Netzwerk eines Benutzers.
RDFa zieht Nutzen aus der umfassenden Leistungskraft von RDF
[RDF], dem W3C-Standard für vollständig kompatible
maschinenlesbare Daten. Jedoch wird von Lesern dieses Dokuments nicht
erwartet, dass sie RDF verstehen. Es wird vom Leser erwartet, dass er
grundlegende Kenntnisse von XHTML hat.
1.1 HTML vs. XHTML
Weil XHTML erweiterbar ist, HTML aber nicht, ist RDFa zur Zeit
nur für XHTML 1.1 spezifiziert. Autoren können
RDFa-Bezeichner gerne in HTML4 verwenden: Der Aufbau von RDFa erwartet
diesen Anwendungsfall und die meisten RDFa-Parser werden RDFa-Attribute
in jeder HTML-Version erkennen. Die Autoren kennen keinen veröffentlichten
Internet-Browser, der ein HTML-Dokument nach Zugabe von RDFa-Bezeichnern nicht
in der erwarteten Weise darstellen wird. Jedoch sollte Autoren bewusst sein,
dass RDFa in HTML4 zur Zeit nicht gültig ist. RDFa-Attribute sind
gültig in XHTML, wenn die DTD XHTML1.1+RDFa verwendet wird.
2 XHTML würzen
Stelle Dir Alice vor, eine Bloggerin, die eine Mischung aus beruflichen
und persönlichen Artikeln unter http://example.com/alice
veröffentlicht. Wir werden Bezeichner-Beispiele erzeugen, um
zu zeigen, wie Alice RDFa verwenden kann. Der gesamte Quelltext
dieser Beispiele kann
gesondert
angeschaut werden.
2.1 Eine Lizenz für Ihre Arbeit
In der Fußzeile ihres Blogs erklärt Alice, dass ihr Inhalt
frei wiederverwendet werden kann, sofern sie die gebührende Anerkennung
bekommt, wenn ihre Artikel zitiert werden. Der XHTML-Quelltext beinhaltet
einen Verweis zu der Creative Commons-Lizenz [CC]:
...
Der gesamte Inhalt dieser Seite steht unter einer
<a href="http://creativecommons.org/licenses/by/3.0/">
Creative Commons-Lizenz
</a>.
Ein Mensch versteht diesen Satz eindeutig, insbesondere die
Bedeutung des Verweises in Bezug auf das aktuelle Dokument:
er zeigt auf die Lizenz des Dokuments, die Bedingungen unter denen
die Inhalte der Seite vertrieben werden. Wenn Bob die Seite von Alice
besucht, sieht sein Browser leider nur einen einfachen Verweis, der genauso
gut auf einen Freund von Alice oder auf ihren Lebenslauf verweisen
könnte. Damit Bobs Browser versteht, dass dieser Verweis auf die
Lizenzbedingungen des Dokuments zeigt, muss Alice etwas Würze
hinzufügen, einen Hinweis von welcher Art dieser Verweis ist.
Sie kann diese Würze mit dem Attribut rel (welches wir als
@rel bezeichnen werden, um das Wort Attribut nicht zu oft zu
verwenden) hinzufügen, welches die Beziehung zwischen der
aktuellen und der verknüpften Seite definiert. Der Wert des Attributs ist
license, ein XHTML-Schlüsselwort, das für genau diesen
Zweck reserviert ist:
...
Der gesamte Inhalt dieser Seite steht unter einer
<a rel="license" ref="http://creativecommons.org/licenses/by/3.0/">
Creative Commons-Lizenz
</a>.
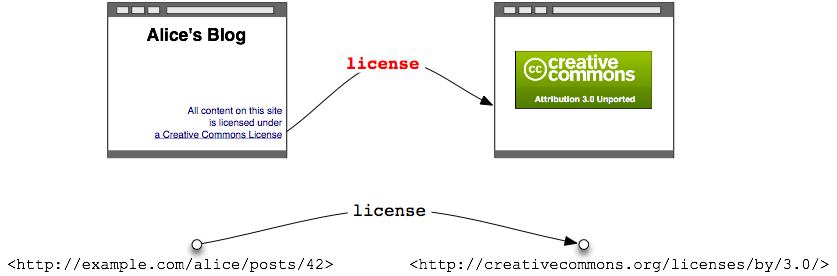
Mit dieser kleinen Aktualisierung wird Bobs Browser nun verstehen, dass
dieser Verweis Würze bekommen hat: er zeigt auf die Lizenz des Blogs.
Ein Verweis mit Würze: der Verweis zeigt auf
die Lizenz der Internetseite. Wir können Internetseiten als Knoten
darstellen, den Verweis als einen Pfeil, der diese Knoten verbindet, und
die Würze des Verweises ist die Beschriftung auf diesem Pfeil.
 |
2.2 Den Titel und den Autor benennen
Alice ist glücklich, dass die Zugabe von XHTML-Würze dazu
führt, dass Bob die Urheberrechtlizenz zu ihrer Arbeit ziemlich einfach
findet. Aber was ist mit dem Titel des Artikels und dem Namen des Autors?
Hier möchte Alice, anstatt einen Verweis zu erweitern, bestehenden
Text innerhalb der Seite erweitern. Der Titel ist eine Überschrift und ihr
Name ist eine Unterüberschrift:
<div>
<h2>The trouble with Bob</h2>
<h3>Alice</h3>
...
</div>
Um anzuzeigen, dass h2 den Titel der Seite repräsentiert
und h3 den Autor, verwendet Alice @property, ein
Attribut, das von RDFa für den bestimmten Zweck eingeführt wird,
bestehenden Text in XHTML-Seiten zu bezeichnen.
<div xmlns:dc="http://purl.org/dc/elements/1.1/">
<h2 property="dc:title">The trouble with Bob</h2>
<h3 property="dc:creator">Alice</h3>
...
</div>
Warum werden dc:creator und dc:title verwendet
und nicht einfach creator und title? Wie sich
zeigt, hat XHTML keine reservierten Schlüsselworte für diese beiden
Konzepte. Alice könnte forsch property="title" schreiben,
aber wie weiß ein Programm, das dieses liest, ob "title" hier Bezug auf
den Titel einer Arbeit, eine Berufsbezeichnung oder einen Titel auf eine
Immobilie nimmt? Und wenn jeder Internetautor seine eigenen kurzen
Schlüsselworte fordern würde, die Welt der verfügbaren
Eigenschaften wäre ein ziemliches Schlamassel, ein wenig wie alle
Dokumente auf dem Desktop eines Computers zu speichern, ohne eine
Verzeichnisstruktur, die sie organisiert.
Um ein wenig Ordnung durchzusetzen, erkennt RDFa property="title"
nicht. Stattdessen muss Alice ein Verzeichnis irgendwo im Internet
angeben, einfach mit einer URL, von der die besonderen Konzepte für
creator und title, die sie ausdrücken
möchte, importiert werden. Glücklicherweise hat die
Dublin Core-Gemeinschaft schon ein Vokabular mit hilfreichen Konzepten
zur Dokumentbeschreibung definiert, eingeschlossen sowohl creator
als auch title, in diesem bedeutet title in der Tat:
der Titel einer Arbeit. Daraus folgt, Alice:
- importiert das Dublin Core-Vokabular mit
xmlns:dc="http://purl.org/dc/elements/1.1/"
und bindet damit das Präfix dc an den URL
http://purl.org/dc/elements/1.1/ und
- verwendet
dc:creator und dc:title. Dies
sind Abkürzungen für die vollständigen URLs
http://purl.org/dc/elements/1.1/creator und
http://purl.org/dc/elements/1.1/title.
In RDFa sind alle Eigenschaftsnamen in der Tat URLs.
Literaleigenschaften: Mit RDFa kann Alice nicht nur
einen URL mit einem anderen URL verknüpfen – zum Beispiel, um ihren
Blogeingangs-URL mit dem URL der Creative Commons-Lizenz zu verknüpfen
– sie kann auch einen URL mit einer Zeichenkette, wie "The Trouble
with Bob", verknüpfen. Alle Pfeile sind mit dem entsprechenden
Eigenschaftsnamen beschriftet, welcher ebenso ein URL ist.
|
2.3 Mehrere Einträge pro Seite
Der Blog von Alice hat natürlich mehrere Einträge. Manchmal
schreibt auch die Schwester von Alice, Eve, Gasteinträge. Die Titelseite
des Blogs listet die zehn letzten Einträge, jeder mit seinem eigenen
Titel, Autor und seinem einleitenden Abschnitt. Wie soll Alice dann den Titel
eines jeden Eintrags einzeln bezeichnen, wenn sie alle innerhalb der
gleichen Internetseite erscheinen? RDFa bietet @about, ein
Attribut zur Angabe des exakten URL, für den die enthaltenen
RDFa-Bezeichner gelten:
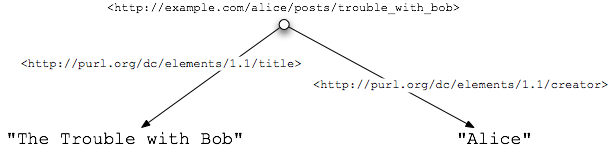
<div xmlns:dc="http://purl.org/dc/elements/1.1/">
<div about="/alice/posts/trouble_with_bob">
<h2 property="dc:title">The trouble with Bob</h2>
<h3 property="dc:creator">Alice</h3>
...
</div>
<div about="/alice/posts/jos_barbecue">
<h2 property="dc:title">Jo's Barbecue</h2>
<h3 property="dc:creator">Eve</h3>
...
</div>
...
</div>
Wir können dies wieder einmal als ein Diagramm darstellen, das
URLs an Eigenschaften bindet:
Mehrere Einträge pro Seite: jeder Blog-Eintrag
wird von seinem eigenen Knoten repräsentiert, jedem sind Eigenschaften
angehängt. Hier haben wir zur Beschriftung der Pfeile die
Abkürzungen verwendet, um Platz zu sparen und das Diagramm
übersichtlicher zu machen. Die tatsächlichen Beschriftungen
sind immer die vollständigen URLs.

|
Alice kann die gleiche Technik verwenden, um ihrem Freund Bob die
gebührende Anerkennung zu zollen, wenn sie eines seiner Fotos
postet:
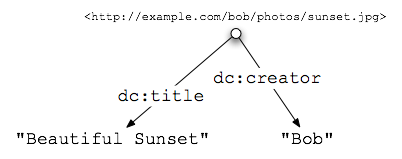
<div about="/alice/posts/trouble_with_bob">
<h2 property="dc:title">The trouble with Bob</h2>
The trouble with Bob is that he takes much better photos than I do:
<div about="http://example.com/bob/photos/sunset.jpg">
<img src="http://example.com/bob/photos/sunset.jpg" />
<span property="dc:title">Beautiful Sunset</span>
by <span property="dc:creator">Bob</span>.
</div>
</div>
Beachte wie der innerste @about-Wert
http://example.com/bob/photos/sunset.jpg den äußeren
Wert /alice/posts/trouble_with_bob für alle Bezeichner
innerhalb des innersten div "überschreibt". Und wieder
einmal als ein Diagramm, das in abstrakter Weise die zu Grunde liegenden
Daten dieser neuen Bezeichner repräsentiert:
Ein Foto beschreiben
|
3 Tiefer hinein gehen
Zusätzlich möchte Alice Informationen über sich selbst
(E-Mail-Adresse, Telefonnummer usw.) auf einfachem Wege für die
Software zur Kontaktverwaltung ihrer Freunde verfügbar machen. Diesmal,
anstatt die Eigenschaften einer Internetseite zu beschreiben, wird sie
die Eigenschaften einer Person beschreiben: Alice selbst. Um dies zu tun,
fügt sie eine tiefere Struktur hinzu, so dass sie mehrere Dinge
verknüpfen kann, die ihrerseits Eigenschaften haben.
3.1 Kontaktinformationen
Alice hat bereits Kontaktinformationen in ihrem Blog angegeben.
<div>
<p>
Alice Birpemswick
</p>
<p>
Email: <a href="mailto:alice@example.com">alice@example.com</a>
</p>
<p>
Phone: <a href="tel:+1-617-555-7332">+1 617.555.7332</a>
</p>
</div>
Das Dublin Core-Vokabular enthält keine Eigenschaftsnamen zur
Beschreibung, aber das Friend-of-a-Friend-Vokabular
[FOAF]. In RDFa ist es alltäglich und einfach
verschiedene Vokabulare in einer einzigen Seite zu kombinieren. Alice
importiert das FOAF-Vokabular und deklariert eine foaf:Person.
Für diesen Zweck verwendet Alice @typeof, ein RDFa-Attribut,
das insbesondere dazu bestimmt ist, neue Dateneinheiten eines
bestimmten Typs zu deklarieren:
<div typeof="foaf:Person" xmlns:foaf="http://xmlns.com/foaf/0.1/">
...
Dann kann Alice angeben, welcher Inhalt auf der Seite ihren vollen
Namen, ihre E-Mail-Adresse und ihre Telefonnummer repräsentiert:
<div typeof="foaf:Person" xmlns:foaf="http://xmlns.com/foaf/0.1/">
<p property="foaf:name">
Alice Birpemswick
</p>
<p>
Email: <a rel="foaf:mbox" href="mailto:alice@example.com">alice@example.com</a>
</p>
<p>
Phone: <a rel="foaf:phone" href="tel:+1-617-555-7332">+1 617.555.7332</a>
</p>
</div>
Beachten Sie, Alice hat @about nicht angegeben wie sie es
zuvor bei der Zugabe von Metadaten zum Blog-Eintrag angegeben hat. Womit
verbindet sie diese Eigenschaften
dann? In der Tat gibt das @typeof des einschließenden
div indirekt das Subjekt der Eigenschaften an, die innerhalb jenes
divs bezeichnet sind. Der Name, die E-Mail-Adresse und die
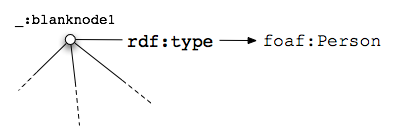
Telefonnummer werden mit einem neuen Knoten des Typs foaf:Person
verbunden. Dieser Knoten hat keinen identifizierenden URL, deshalb wird
er leerer Knoten genannt.
Ein leerer Knoten: leere Knoten werden nicht durch
einen URL identifiziert. Stattdessen haben viele von ihnen ein @typeof-Attribut,
das den Datentyp angibt, den sie repräsentieren. Diese Vorgehensweise -
keinen Namen anzugeben, aber einen Typ hinzuzufügen - ist besonders
hilfreich, wenn mehrere Dinge auf einer Seite aufgelistet werden, zum Beispiel
Kalendereinträge, Autoren eines Artikels, Freunde in einem sozialen
Netzwerk und so weiter.
 |
3.2 Soziales Netzwerk
Als Nächstes möchte Alice Informationen über ihre
Freunde hinzufügen, einschließlich mindestens ihrer Namen und
ihrer Homepages. Ihr Quelltext in XHTML lautet:
<div>
<ul>
<li>
<a href="http://example.com/bob/">Bob</a>
</li>
<li>
<a href="http://example.com/eve/">Eve</a>
</li>
<li>
<a href="http://example.com/manu/">Manu</a>
</li>
</ul>
</div>
Zuerst gibt Alice an, dass all diese Freunde dem Typ
foaf:Person angehören.
<div xmlns:foaf="http://xmlns.com/foaf/0.1/">
<ul>
<li typeof="foaf:Person">
<a href="http://example.com/bob/">Bob</a>
</li>
<li typeof="foaf:Person">
<a href="http://example.com/eve/">Eve</a>
</li>
<li typeof="foaf:Person">
<a href="http://example.com/manu/">Manu</a>
</li>
</ul>
</div>
Über das Deklarieren des Datentyps, mit dem wir es zu tun haben,
hinaus, erzeugt jedes @typeof einen neuen leeren Knoten mit seinen
eigenen individuellen Eigenschaften, all das ohne URL-Identifizierer anzugeben.
So kann Alice einfach die Internetseite (engl. homepage) eines jeden
Freundes angeben:
<div xmlns:foaf="http://xmlns.com/foaf/0.1/">
<ul>
<li typeof="foaf:Person">
<a rel="foaf:homepage" href="http://example.com/bob/">Bob</a>
</li>
<li typeof="foaf:Person">
<a rel="foaf:homepage" href="http://example.com/eve/">Eve</a>
</li>
<li typeof="foaf:Person">
<a rel="foaf:homepage" href="http://example.com/manu/">Manu</a>
</li>
</ul>
</div>
Und natürlich jeden einzelnen Namen (engl. name) ihrer Freunde:
<div xmlns:foaf="http://xmlns.com/foaf/0.1/">
<ul>
<li typeof="foaf:Person">
<a property="foaf:name" rel="foaf:homepage" href="http://example.com/bob/">Bob</a>
</li>
<li typeof="foaf:Person">
<a property="foaf:name" rel="foaf:homepage" href="http://example.com/eve/">Eve</a>
</li>
<li typeof="foaf:Person">
<a property="foaf:name" rel="foaf:homepage" href="http://example.com/manu/">Manu</a>
</li>
</ul>
</div>
Mit @property gibt Alice an, dass die verknüpften
Texte ("Bob", "Eve" und "Manu") in der Tat die Namen ihrer Freunde sind. Mit
@rel gibt sie an, dass die anklickbaren Verweise die Homepages
ihrer Freunde sind. Alice ist ekstatisch, dass sie mit so wenig
zusätzlichen Bezeichnern in der Lage ist, beides vollständig
auszudrücken, eine für Menschen angenehm zu lesende Seite und
einen maschinenlesbaren Datensatz.
Alice hat es satt, in jedem neuen sozialen Netzwerk immer wieder die
Informationen über ihre Freunde anzugeben. Mit RDFa kann sie ihre
Freundschaften auf ihrer eigenen Internetseite angeben, und sie kann den
Anwendungen sozialer Netzwerke erlauben, diese automatisch zu lesen.
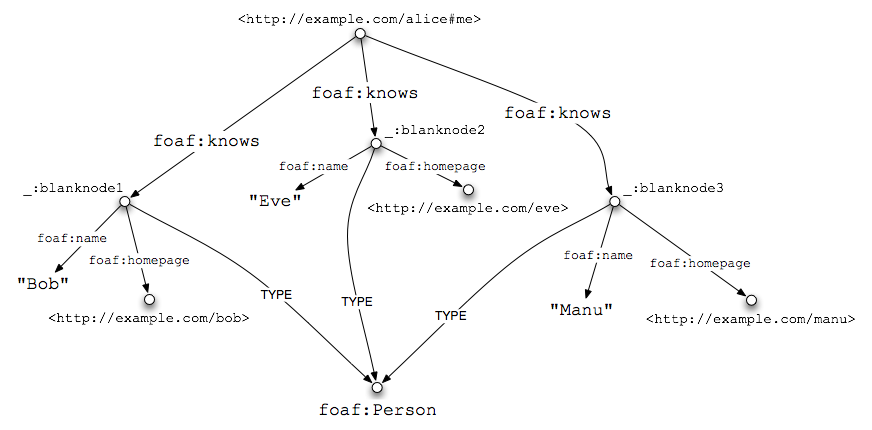
Soweit hat Alice drei Individuen in der Liste, hat aber noch nicht
ihre Beziehung zu ihnen angegeben; sie könnten ihre Freunde sein,
oder sie könnten ihre beliebtesten Dichter des 17ten Jahrhunderts
sein. Um anzugeben, dass sie jene in der Tat kennt, verwendet sie die
FOAF-Eigenschaft foaf:knows:
<div xmlns:foaf="http://xmlns.com/foaf/0.1/" about="#me" rel="foaf:knows">
<ul>
<li typeof="foaf:Person">
<a property="foaf:name" rel="foaf:homepage" href="http://example.com/bob">Bob</a>
</li>
<li typeof="foaf:Person">
<a property="foaf:name" rel="foaf:homepage" href="http://example.com/eve">Eve</a>
</li>
<li typeof="foaf:Person">
<a property="foaf:name" rel="foaf:homepage" href="http://example.com/manu">Manu</a>
</li>
</ul>
</div>
Die einmalige Verwendung von rel="foaf:knows" ist
genug, um Bob, Eve und Manu mit Alice zu verknüpfen. Das wird dank dem
RDFa-Konzept des Verkettens erreicht: weil das @rel im
äußeren Element ohne ein entsprechendes @href steht,
wird es mit jedem enthaltenen Knoten verknüpft, in diesem Fall sind das
die drei Knoten, die von @typeof definiert sind. (Das
@about="#me" ist eine FOAF/RDF-Vereinbarung: der URL, der die
Person Alice repräsentiert, ist
http://example.com/alice#me. Es sollte nicht mit der Homepage
von Alice verwechselt werden, http://example.com/alice. Du bist,
was Du isst, aber Du bist weit mehr als nur Deine Homepage.)
Das soziale Netzwerk von Alice
 |
4 Du hast etwas über RDF gesagt?
RDF, das Resource Description Framework, ist exakt die abstrakte
Datenrepräsentation, die wir in den Beispielen als Schaubild
ausgemalt haben. Jeder Pfeil im Schaubild wird als ein
Subjekt-Prädikat-Objekt-Dreier repräsentiert: das Subjekt ist
der Knoten zu Beginn des Pfeils, das Prädikat ist der Pfeil selbst und
das Objekt ist der Knoten oder das Literal am Ende des Pfeils. Ein RDF-Datensatz
wird oft ein "RDF Graph" genannt und wird gewöhnlich in etwas
gespeichert, das oft "Triple Store" genannt wird.
Ziehe das erste beispielhafte Schaubild in Betracht:
Die beiden RDF-Dreier für dieses Schaubild werden mit der
Notation3-Syntax [N3] wie folgt geschrieben:
<http://www.example.com/alice/posts/trouble_with_bob>
<http://purl.org/dc/elements/1.1/title> "The Trouble with Bob";
<http://purl.org/dc/elements/1.1/creator> "Alice" .
Die TYPE-Pfeile, die wir gemalt haben, unterscheiden sich nicht von
anderen Pfeilen, nur ihre Beschriftung ist eine
Haupteigenschaft von RDF rdf:type. Der
rdf-Namensraum hierbei ist
<http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
Das Beispiel der Kontaktinformationen von oben sollte demnach wie folgt
in einem Diagramm dargestellt werden:
 |
Das Wesentliche in RDF ist es, eine universelle Sprache zur Verfügung
zu stellen, um Daten auszudrücken. Eine Einheit Daten kann jegliche
Anzahl von Feldern haben und Feldnamen sind URLs, die von jedem Autor
wiederverwendet werden können, sehr ähnlich wie jeder Autor zu jeder
Internetseite verweisen kann, selbst zu denen, die er nicht selbst
erstellt hat. Mit gegebenen Daten in der Form von RDF-Dreiern, gesammelt
von verschiedensten Orten, und unter der Verwendung der RDF-Abfragesprache
SPARQL [SPARQL], kann jemand nach "Freunden von Alice suchen,
die Dinge erzeugt haben, deren Titel das Wort 'Bob' enthält",
egal ob diese Dinge Blog-Einträge,
Videos, Kalendereinträge oder andere Datenypen sind, an die wir bis
jetzt noch nicht gedacht haben.
RDF ist eine abstrakte maschinenlesbare Datendarstellung, gedacht, um
die Wiederverwendung von Vokabularen zu maximieren. RDFa ist ein Weg,
RDF-Daten innerhalb von XHTML auszudrücken, und zwar durch die
Wiederverwendung von existierenden menschenlesbaren Daten.
4.1 Maßgeschneiderte Vokabulare
Während Alice ihre Seite mit RDFa-Bezeichnern erweitert, könnte
sie die Notwendigkeit entdecken, Daten auszudrücken, zum Beispiel ihre
Lieblingsfotos, die nicht von existierendem Vokabular wie Dublin Core oder
FOAF abgedeckt werden.
Die Anweisungen, wie ein RDF-Schema erzeugt wird, sind in Abschnitt 5
von RDF Primer [RDF-SCHEMA-PRIMER]
verfügbar. Auf einer hohen Ebene schließt die Erzeugung
eines RDF-Schemas für RDFa Folgendes ein:
- Einen URL auswählen, unter dem das Vokabular residieren wird,
zum Beispiel
http://example.com/photos/vocab#.
- Ein RDF-Dokument verteilen, unter jener URL, welches die
Klassen und Eigenschaften definiert, aus der sich das Vokabular
zusammensetzt. Zum Beispiel könnte Alice die Klassen
Photo
und Camera definieren wollen, wie auch die Eigenschaft
takeWith, die das Foto mit der Kamera verbindet, mit der
es gemacht wurde.
- Das Vokabular in XHTML+RDFa mit dem gebräuchlichen Mechanismus zur
Präfix-Deklaration verwenden, zum Beispiel
xmlns:photo="http://example.com/photos/vocab#"
und typeof="photo:Camera".
Es ist es wert zu sagen, dass jede Person, die ein Dokument im Internet
veröffentlichen kann, auch ein RDF-Vokabular veröffentlichen kann,
und so neue Datenfelder definieren kann, die sie eventuell ausdrücken
möchte. RDF und RDFa gestatten die vollständig verteilte
Erweiterbarkeit von Vokabularen.
5 Mehr herausfinden
Mehr Beispiele, Verweise zu Hilfsprogrammen und Informationen, wie
man sich engagieren kann, können im
RDFa-Wiki gefunden werden.
6 Anerkennungen
Dieses Dokument ist die Arbeit der Arbeitsgruppe RDF-in-HTML,
einschließlich (in alphabetischer Reihenfolge) Ben Adida,
Mark Birbeck, Jeremy Carroll,
Michael Hausenblas, Shane McCarron, Steven Pemberton, Manu Sporny,
Ralph Swick und Elias Torres. Diese Arbeit wäre nicht möglich
gewesen ohne die Hilfe der Arbeitsgruppe Semantic Deployment und ihrer
früheren Inkarnation, der Arbeitsgruppe Semantic Web Deployment
and Best Practices, insbesondere derer Vorsitzenden Tom Baker und Guus
Schreiber (und zuvor David Wood), der XHTML2-Arbeitsgruppe, Eric Miller,
dem früheren Chef der Semantic Web Activity, und Ivan
Herman, dem aktuellen Chef der Semantic Web Activity. Frühere
Versionen dieses Dokuments wurden offiziell von Gary Ng und David Booth
überprüft, und aktuellere Versionen von Diego Berrueta und
Ed Summers, jeder von ihnen hat die Arbeit mit einblickenden Kommentaren
erheblich verbessert. Bob DuCharme hat die Arbeit ebenso überprüft
und hilfreiche Kommentare abgegeben.
Änderungen
Die vorherige Version dieses Dokuments war eine signifikante Neuauflage
in Bezug auf Eindeutigkeit und Einfachheit. Diese Version beinhaltet nur
eine kleine handvoll Aktualisierungen:
- einige Tippfehler verbessert
- "HTML" in "XHTML" geändert und Abschnitt 1.1 hinzugefügt, der
die Situation erklärt.
- Abschnitt 4.1 über maßgeschneiderte Vokabulare
hinzugefügt.